
通用搜索引擎的處理對象是互聯網網頁,目前網頁數量以百億計,搜索引擎的網絡爬蟲能夠高效地將海量的網頁數據傳下載到本地,在本地形成互聯網網頁的鏡像備份。它是搜索引擎系統中很關鍵也很基礎的構件。
1.網絡爬蟲本質就是瀏覽器http請求。
瀏覽器和網絡爬蟲是兩種不同的網絡客戶端,都以相同的方式來獲取網頁:
1)首先,客戶端程序連接到域名系統(DNS)服務器上,DNS服務器將主機名轉換成ip地址。
2)接下來,客戶端試著連接具有該IP地址的服務器。服務器上可能有多個不同進程程序在運行,每個進程程序都在監聽網絡以發現新的選接。各個進程監聽不同的網絡端口(port).端口是一個l6位的數卞,用來辨識不同的服務。Http請求一般默認都是80端口。
3)一旦建立連接,客戶端向服務器發送一個http請求,服務器接收到請求后,返回響應結果給客戶端。
4)客戶端關閉該連接。
詳細了解http工作原理:網絡互聯參考模型(詳解)和Apache運行機制剖析
2.搜索引擎爬蟲架構
但是瀏覽器是用戶主動操作然后完成HTTP請求,而爬蟲需要自動完成http請求,網絡爬蟲需要一套整體架構完成工作。
盡管爬蟲技術經過幾十年的發展,從整體框架上已相對成熟,但隨著互聯網的不斷發展,也面臨著一些有挑戰性的新問題。通用爬蟲框架如下圖:
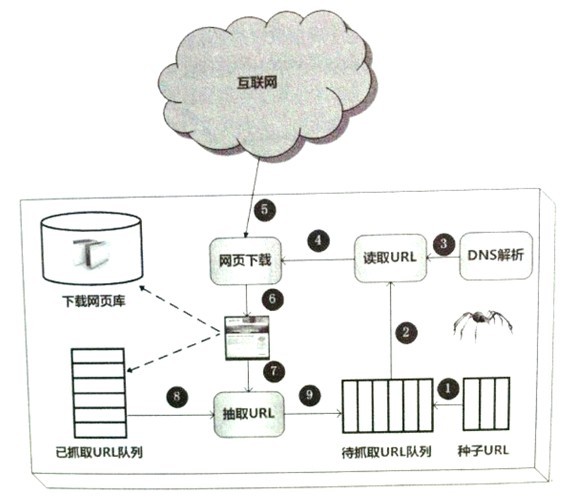
通用的爬蟲框架流程:
1)首先從互聯網頁面中精心選擇一部分網頁,以這些網頁的鏈接地址作為種子URL;
2)將這些種子URL放入待抓取URL隊列中;
3)爬蟲從待抓取URL隊列依次讀取,并將URL通過DNS解析,把鏈接地址轉換為網站服務器對應的IP地址。
4)然后將IP地址和網頁相對路徑名稱交給網頁下載器,
5)網頁下載器負責頁面內容的下載。
6)對于下載到本地的網頁,一方面將其存儲到頁面庫中,等待建立索引等后續處理;另一方面將下載網頁的URL放入己抓取URL隊列中,這個隊列記載了爬蟲系統己經下載過的網頁URL,以避免網頁的重復抓取。
7)對于剛下載的網頁,從中抽取出所包含的所有鏈接信息,并在已抓取URL隊列中檢査,如果發現鏈接還沒有被抓取過,則將這個URL放入待抓取URL隊歹!
8,9)末尾,在之后的抓取調度中會下載這個URL對應的網頁,如此這般,形成循環,直到待抓取URL隊列為空.
3.爬蟲抓取策略
在爬蟲系統中,待抓取URL隊列是很重要的一部分。待抓取URL隊列中的URL以什么樣的順序排列也是一個很重要的問題,因為這涉及到先抓取那個頁面,后抓取哪個頁面。而決定這些URL排列順序的方法,叫做抓取策略。
3.1深度優先搜索策略(順藤摸瓜)
即圖的深度優先遍歷算法。網絡爬蟲會從起始頁開始,一個鏈接一個鏈接跟蹤下去,處理完這條線路之后再轉入下一個起始頁,繼續跟蹤鏈接。
我們使用圖的方式來說明:
我們假設互聯網就是張有向圖,圖中每個頂點代表一個網頁。設初始狀態是圖中所有頂點未曾被訪問,則深度優先搜索可從圖中某個頂點發v出發,訪問此頂點,然后依次從v的未被訪問的鄰接點出發深度優先遍歷圖,直至圖中所有和v有路徑相通的頂點都被訪問到;若此時圖中尚有頂點未被訪問,則另選圖中一個未曾被訪問的頂點作起始點,重復上述過程,直至圖中所有頂點都被訪問到為止。
以如下圖的無向圖G1為例,進行圖的深度優先搜索:
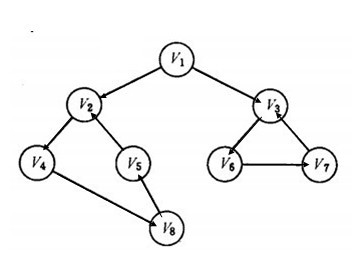
G1
搜索過程:
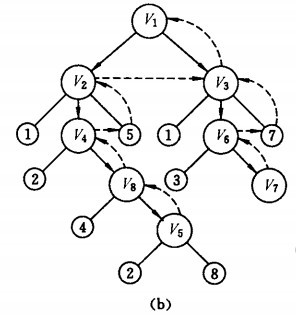
假設從頂點頁面v1出發進行搜索抓取,在訪問了頁面v1之后,選擇鄰接點頁面v2。因為v2未曾訪問,則從v2出發進行搜索。依次類推,接著從v4、v8、v5出發進行搜索。在訪問了v5之后,由于v5的鄰接點都已被訪問,則搜索回到v8。由于同樣的理由,搜索繼續回到v4,v2直至v1,此時由于v1的另一個鄰接點未被訪問,則搜索又從v1到v3,再繼續進行下去由此,得到的頂點訪問序列為:
V1→V2→V3→V4→V5→V6→V7
3.2廣度優先搜索策略
寬度優先遍歷策略的基本思路是,將新下載網頁中發現的鏈接直接插入待抓取URL隊列的末尾。也就是指網絡爬蟲會先抓取起始網頁中鏈接的所有網頁,然后再選擇其中的一個鏈接網頁,繼續抓取在此網頁中鏈接的所有網頁。該算法的設計和實現相對簡單。在目前為覆蓋盡可能多的網頁,一般使用廣度優先搜索方法。也有很多研究將廣度優先搜索策略應用于聚焦爬蟲中。其基本思想是認為與初始URL在一定鏈接距離內的網頁具有主題相關性的概率很大。另外一種方法是將廣度優先搜索與網頁過濾技術結合使用,先用廣度優先策略抓取網頁,再將其中無關的網頁過濾掉。這些方法的缺點在于,隨著抓取網頁的增多,大量的無關網頁將被下載并過濾,算法的效率將變低。
還是以上面的圖為例,抓取過程如下:
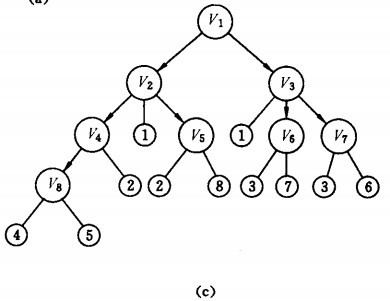
廣度搜索過程:
首先訪問頁面v1和v1的鄰接點v2和v3,然后依次訪問v2的鄰接點v4和v5及v3的鄰接點v6和v7,最后訪問v4的鄰接點v8。由于這些頂點的鄰接點均已被訪問,并且圖中所有頂點都被訪問,由些完成了圖的遍歷。得到的頂點訪問序列為:
v1→v2→v3→v4→v5→v6→v7→v8
和深度優先搜索類似,在遍歷的過程中也需要一個訪問標志數組。并且,為了順次訪問路徑長度為2、3、…的頂點,需附設隊列以存儲已被訪問的路徑長度為1、2、…的頂點。
3.2最佳優先搜索策略
最佳優先搜索策略按照一定的網頁分析算法,預測候選URL與目標網頁的相似度,或與主題的相關性,并選取評價最好的一個或幾個URL進行抓取。
3.3.反向鏈接數策略
反向鏈接數是指一個網頁被其他網頁鏈接指向的數量。反向鏈接數表示的是一個網頁的內容受到其他人的推薦的程度。因此,很多時候搜索引擎的抓取系統會使用這個指標來評價網頁的重要程度,從而決定不同網頁的抓取先后順序。
在真實的網絡環境中,由于廣告鏈接、作弊鏈接的存在,反向鏈接數不能完全等他我那個也的重要程度。因此,搜索引擎往往考慮一些可靠的反向鏈接數。
3.4.PartialPageRank策略,即最佳優先搜索策略
PartialPageRank算法借鑒了PageRank算法的思想:按照一定的網頁分析算法,預測候選URL與目標網頁的相似度,或與主題的相關性,并選取評價最好的一個或幾個URL進行抓取,即對于已經下載的網頁,連同待抓取URL隊列中的URL,形成網頁集合,計算每個頁面的PageRank值,計算完之后,將待抓取URL隊列中的URL按照PageRank值的大小排列,并按照該順序抓取頁面。
它只訪問經過網頁分析算法預測為“有用”的網頁。存在的一個問題是,在爬蟲抓取路徑上的很多相關網頁可能被忽略,因為最佳優先策略是一種局部最優搜索算法。因此需要將最佳優先結合具體的應用進行改進,以跳出局部最優點。研究表明,這樣的閉環調整可以將無關網頁數量降低30%~90%。
如果每次抓取一個頁面,就重新計算PageRank值,一種折中方案是:每抓取K個頁面后,重新計算一次PageRank值。但是這種情況還會有一個問題:對于已經下載下來的頁面中分析出的鏈接,也就是我們之前提到的未知網頁那一部分,暫時是沒有PageRank值的。為了解決這個問題,會給這些頁面一個臨時的PageRank值:將這個網頁所有入鏈傳遞進來的PageRank值進行匯總,這樣就形成了該未知頁面的PageRank值,從而參與排序。
3.5.OPIC策略策略
該算法實際上也是對頁面進行一個重要性打分。在算法開始前,給所有頁面一個相同的初始現金(cash)。當下載了某個頁面P之后,將P的現金分攤給所有從P中分析出的鏈接,并且將P的現金清空。對于待抓取URL隊列中的所有頁面按照現金數進行排序。
3.6.大站優先策略
對于待抓取URL隊列中的所有網頁,根據所屬的網站進行分類。對于待下載頁面數多的網站,優先下載。這個策略也因此叫做大站優先策略。
4.網頁更新策略
互聯網是實時變化的,具有很強的動態性。網頁更新策略主要是決定何時更新之前已經下載過的頁面。常見的更新策略又以下三種:
1.歷史參考策略
顧名思義,根據頁面以往的歷史更新數據,預測該頁面未來何時會發生變化。一般來說,是通過泊松過程進行建模進行預測。
2.用戶體驗策略
盡管搜索引擎針對于某個查詢條件能夠返回數量巨大的結果,但是用戶往往只關注前幾頁結果。因此,抓取系統可以優先更新那些現實在查詢結果前幾頁中的網頁,而后再更新那些后面的網頁。這種更新策略也是需要用到歷史信息的。用戶體驗策略保留網頁的多個歷史版本,并且根據過去每次內容變化對搜索質量的影響,得出一個平均值,用這個值作為決定何時重新抓取的依據。
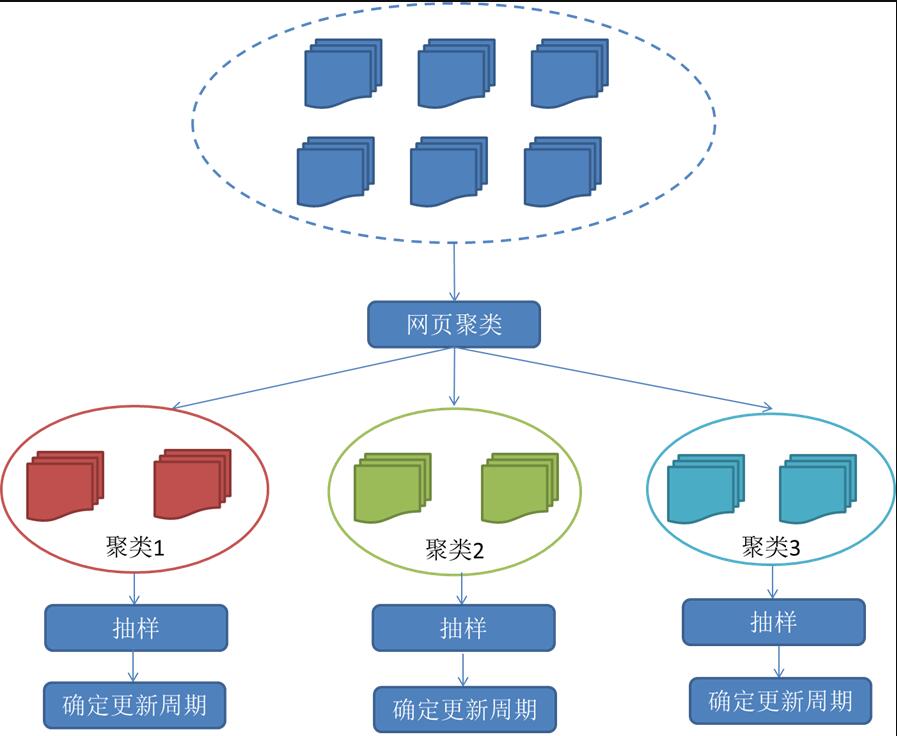
3.聚類抽樣策略
前面提到的兩種更新策略都有一個前提:需要網頁的歷史信息。這樣就存在兩個問題:第一,系統要是為每個系統保存多個版本的歷史信息,無疑增加了很多的系統負擔;第二,要是新的網頁完全沒有歷史信息,就無法確定更新策略。
這種策略認為,網頁具有很多屬性,類似屬性的網頁,可以認為其更新頻率也是類似的。要計算某一個類別網頁的更新頻率,只需要對這一類網頁抽樣,以他們的更新周期作為整個類別的更新周期。基本思路如圖:
5.云存儲文檔
應用的知識:
1,GFS,使用GFS分布式文件系統存儲海量文檔。
2,BitTable,在GFS的基礎上構建BitTable的數據模型;
3,MegaStore存儲模型又建立在BitTable之上的存儲和計算模型。
4,Map/Reduce云計算模型和系統計算框架。
4.1BitTable存儲原始的網頁信息
如圖4-1所示的邏輯模型,示例crawldbtable用于存儲爬蟲抓取的網頁信息,
其中:RowKey為網頁的URL,出于排序效率考慮,URL中主機域名字符順序往往被反置,如www.facebook.com被處理為com.facebook.www;
ColumnFamily包括title、content、anchor,其中tile保存網頁的標題,content保存網頁html內容,anchor保存網頁被其它網頁引用的鏈接,qualifier就是其它網頁的URL,內容為其它網頁中該鏈接的頁面顯示字符,同樣anchor鏈接的URL主機域字符串被反置。對于不同時間獲取的同一網頁的有關內容被打上不同的時間戳Timestampe,如圖縱向座標可以看到不同的版本。
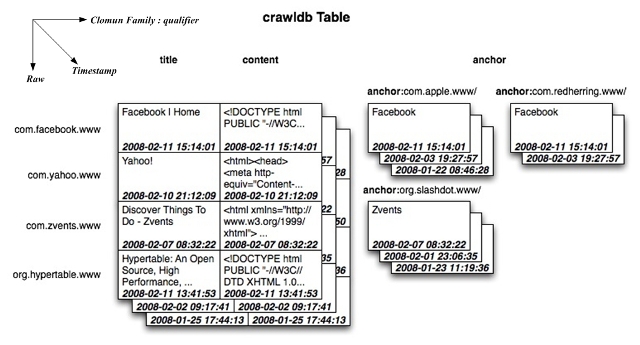
圖4-1CrawldbTable邏輯模型
在實際的存儲中,圖4-1所示的多維邏輯結構會被二維平面化為(Key,Value)對,并且進行排序。在(Key,Value)中,Key由四維鍵值組成,包括:RowKey,ColumnFamily(處理時使用8比特編碼),ColumnQualifier和Timestamp,如圖4-2所示,為Key的實際結構,在對Key進行排序過程中,有最新Timestamp的Key會被排在最前面,flag項用于標明系統需要對該(Key,Value)記錄進行的操作符,如增加、刪除、更新等。
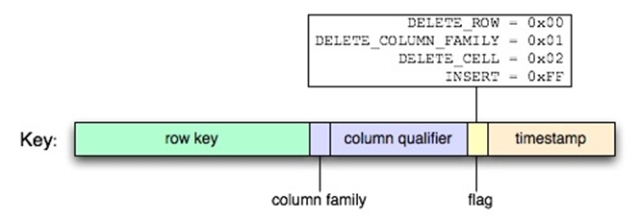
圖4-2key結構圖
如圖4-3是crawldb二維平面化后經過排序的格式。圖中Key列中的信息由RowKey(頁面的URL)、ColumnFamily、ColumnQualifer和Timestamp組成,其中并未顯示Keyflag項,flag項主要用于表項處理。
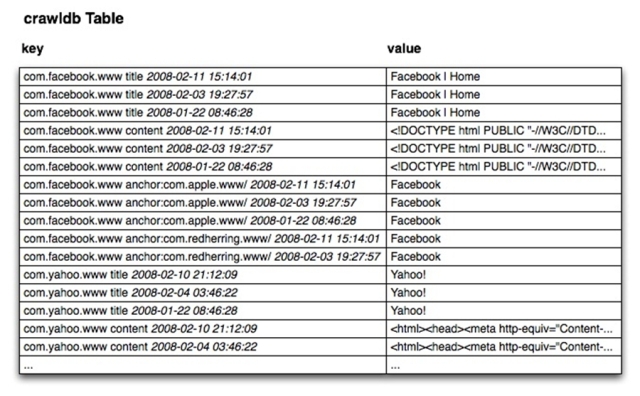
圖4-3crawldb表的key/valuye列表
圖4-4顯示了crawldbtable的CellStore文件格式。CellStore文件中存儲了經過排序后的Key,Value對,物理上,這些數據都被壓縮后存儲,以大約64k大小的塊為單位組織;在文件結尾處,保留有三個索引部分:BloomFilter、塊索引(rowkey+塊在文件內的偏移)、Trailer。

4.2Map/Reduce計算模型處理網頁信息:網頁去重和生成倒排索引
網頁去重我們采用簡單策略,目標是將網頁集合內所有內容相同的網頁找出來,采取對網頁內容取哈希值的方法,比如MD5,如果兩個網頁的MD5值相同,則可以認為兩頁內容完全相同。在Map/Reduce框架下,輸入數據是網頁本身,可以用網頁的URL作為輸入數據的Key,網頁內容是輸入數據的value;Map操作則對每個網頁的內容利用MD5計算哈希值,以這個哈希值作為中間數據的Key,網頁的URL作為中間數據的value:Reduce操作則將相同Key的中間數據對應的URL建立成一個鏈表結構,這個鏈表代表了具有相同網頁內容哈希值的都有哪些網頁。這樣就完成了識別內容相同網頁的任務。
對于建立倒排索引這個任務來說,如圖4-6所示,輸入數據也是網頁,以網頁的DOCID作為輸入數據的Key,網頁中出現的單詞集合是輸入數據的Value;Map操作將輸入數據轉化為(word,DOCID)的形式,即某個單詞作為Key,DOCID作為中間數據的value,其含義是單詞word在DOCID這個網頁出現過;Reduce操作將中間數據中相同Key的記錄融合,得到某個單詞對應的網頁ID列表:
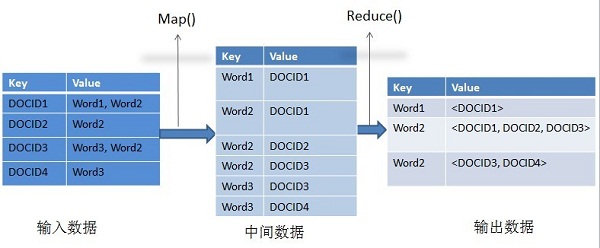
圖4-6
北京愛品特SEO網站優化提供專業的網站SEO診斷服務、SEO顧問服務、SEO外包服務,咨詢電話或微信:13811777897 袁先生 可免費獲取SEO網站診斷報告。
北京網站優化公司 >> SEO資訊 >> SEO技術技巧 >> 搜索引擎原理:網絡爬蟲 本站部分內容來源于互聯網,如有版權糾紛或者違規問題,請聯系我們刪除,謝謝!

售后響應及時
全國7×24小時客服熱線
數據備份
更安全、更高效、更穩定
價格公道精準
項目經理精準報價不弄虛作假
合作無風險
重合同講信譽,無效全額退款




 SEO技術技巧
SEO技術技巧 SEO算法解析
SEO算法解析 公司動態
公司動態 公司簡介
公司簡介 我們的觀點
我們的觀點 為什么選擇我們
為什么選擇我們 企業文化
企業文化 聯系方式
聯系方式 在線留言
在線留言 提交意向表
提交意向表 在線客服
在線客服 來訪路線
來訪路線







