
robots是搜索引擎爬蟲協議,也就是你網站和爬蟲的協議。
簡單的理解:robots是告訴搜索引擎,你可以爬取收錄我的什么頁面,你不可以爬取和收錄我的那些頁面。robots很好的控制網站那些頁面可以被爬取,那些頁面不可以被爬取。
主流的搜索引擎都會遵守robots協議。并且robots協議是爬蟲爬取網站第一個需要爬取的文件。爬蟲爬取robots文件后,會讀取上面的協議,并準守協議爬取網站,收錄網站。
robots文件是一個純文本文件,也就是常見的.txt文件。在這個文件中網站管理者可以聲明該網站中不想被robots訪問的部分,或者指定搜索引擎只收錄指定的內容。因此,robots的優化會直接影響到搜索引擎對網站的收錄情況。
robots文件如下圖

存放目錄
robots文件必須要存放在網站的根目錄下。也就是 域名/robots.txt 是可以訪問文件的。你們也可以嘗試訪問別人網站的robots文件。 輸入域名/robots.txt 即可訪問。
如下圖
robots寫作語法
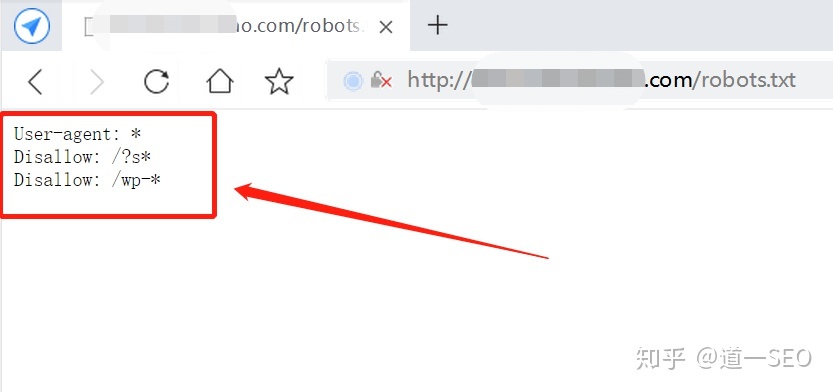
首先我們來看一個范例(下圖)
user-agent這句代碼表示那個搜索引擎準守協議。user-agent后面為搜索機器人名稱,如果是“*”號,則泛指所有的搜索引擎機器人;案例中顯示“User-agent: *” 表示所有搜索引擎準守,*號表示所有。
Disallow是禁止爬取的意思。Disallow后面是不允許訪問文件目錄(你可以理解為路徑中包含改字符、都不會爬取)。案例中顯示“Disallow: /?s*” 表示路徑中帶有“/?s”的路徑都不能爬取。 *代表匹配所有。 這里需要主機。 Disallow空格一個,/必須為開頭。
如果“Disallow: /” 因為所有路徑都包含/ ,所以這表示禁止爬取網站所有內容。
如果沒有被禁止到的路徑,默認為可以被爬取。
關于robots的注意事項
1、不要禁止爬蟲爬取網站的所有,因為從經驗來看,如果屏蔽一次,解封后好一段時間爬蟲都不會來你網站,收錄成為問題。
2、代碼后需要【冒號+空格+斜桿】 ,比如“Disallow: /*?* ”
3、當網站為靜態路徑時,需要屏蔽掉所有動態鏈接。網站中存在一種鏈接被收錄即可,避免一個頁面2個鏈接。代碼如下“Disallow: /*?* ”表示禁止所有帶 ?號的網址被爬取。通常動態網址帶有“?”“=”等。
4、根據自己網站情況定,屏蔽不需要收錄的網址。
北京愛品特SEO網站優化提供專業的網站SEO診斷服務、SEO顧問服務、SEO外包服務,咨詢電話或微信:13811777897 袁先生 可免費獲取SEO網站診斷報告。
北京網站優化公司 >> SEO資訊 >> SEO技術技巧 >> 關于網站robots協議,看這篇就夠了 本站部分內容來源于互聯網,如有版權糾紛或者違規問題,請聯系我們刪除,謝謝!

售后響應及時
全國7×24小時客服熱線
數據備份
更安全、更高效、更穩定
價格公道精準
項目經理精準報價不弄虛作假
合作無風險
重合同講信譽,無效全額退款




 SEO技術技巧
SEO技術技巧 SEO算法解析
SEO算法解析 公司動態
公司動態 公司簡介
公司簡介 我們的觀點
我們的觀點 為什么選擇我們
為什么選擇我們 企業文化
企業文化 聯系方式
聯系方式 在線留言
在線留言 提交意向表
提交意向表 在線客服
在線客服 來訪路線
來訪路線







